

AI in Drug Discovery & Development : The Truth Behind it
AI is already useful in pharma, but only inthe parts of the pipeline where it can reduce uncertainty fast. This guide maps AI methods to each stage, what data you need, what decisions youcan improve, and where models usually fail.
I am writing this with a clinician-researcher lens: AI can speed work up, but it still needs biological and clinical judgment. AI is most valuable where drug R&D isslow, expensive, and full of repeated cycles.
If you aim it at the right bottleneck, even small efficiency gains can save months and large budgets.
Why drug R&D is Slow and Risky ?
Facts & Reality
The pipeline is expensive before humans ever receive a dose. Preclinical (pre-human) out-of-pocket spendis estimated at $430 million perapproved drug.
Source https://healthtechnetwork.com/wp-content/uploads/2017/12/DiMasi.pdf
Clinical risk is even harsher. Across 2011-2020, only 7.9% of drugs entering Phase I ultimately reached approval.
Source https://go.bio.org/rs/490-EHZ-999/images/ClinicalDevelopmentSuccessRates2011_2020.pdf
Time is a bottleneck too, even when trialswork. Median completed trial duration is about 1,150 days in Phase II (~3.2 years) and994 days in Phase III (~2.7 years)
Our World In Data https://ourworldindata.org/grapher/average-study-length-by-phase
A useful reality check: once you reach filing, the odds look much better. The probability from NDA/BLA to approval is 90.6% .Most risk sits earlier.
Source https://go.bio.org/rs/490-EHZ-999/images/ClinicalDevelopmentSuccessRates2011_2020.pdf
Where delays usually happen (what I see in real teams):
· Target validation that does notreplicate across cohorts
· Wet-lab cycles that are slow toplan, run, and interpret
· Hit-to-lead work where youoptimize the wrong property first
· Trial recruitment whereeligibility logic is complex and patient data is messy
What This Guide Will Do
This post connects AI to each stage with:
· The outcome you canrealistically expect
· The data inputs you need
· The validation bar you shoulddemand
· The failure modes that breakmodels in real programs
From my conversations with researchers and medtech founders, the strongest AI wins were not broad platforms.They were narrow, measurable projects like target ID in one pathway, screening for a defined indication, literature miningfor biomarker support, and repurposing known compounds. AI works best when it narrows uncertainty. It does not replace biology.

AI in Pharma :
ML / Deep Learning / NLP / Generative
Most AI in drug discovery discussions fail because teams mix methods and expectations.
Here is the simple breakdown.
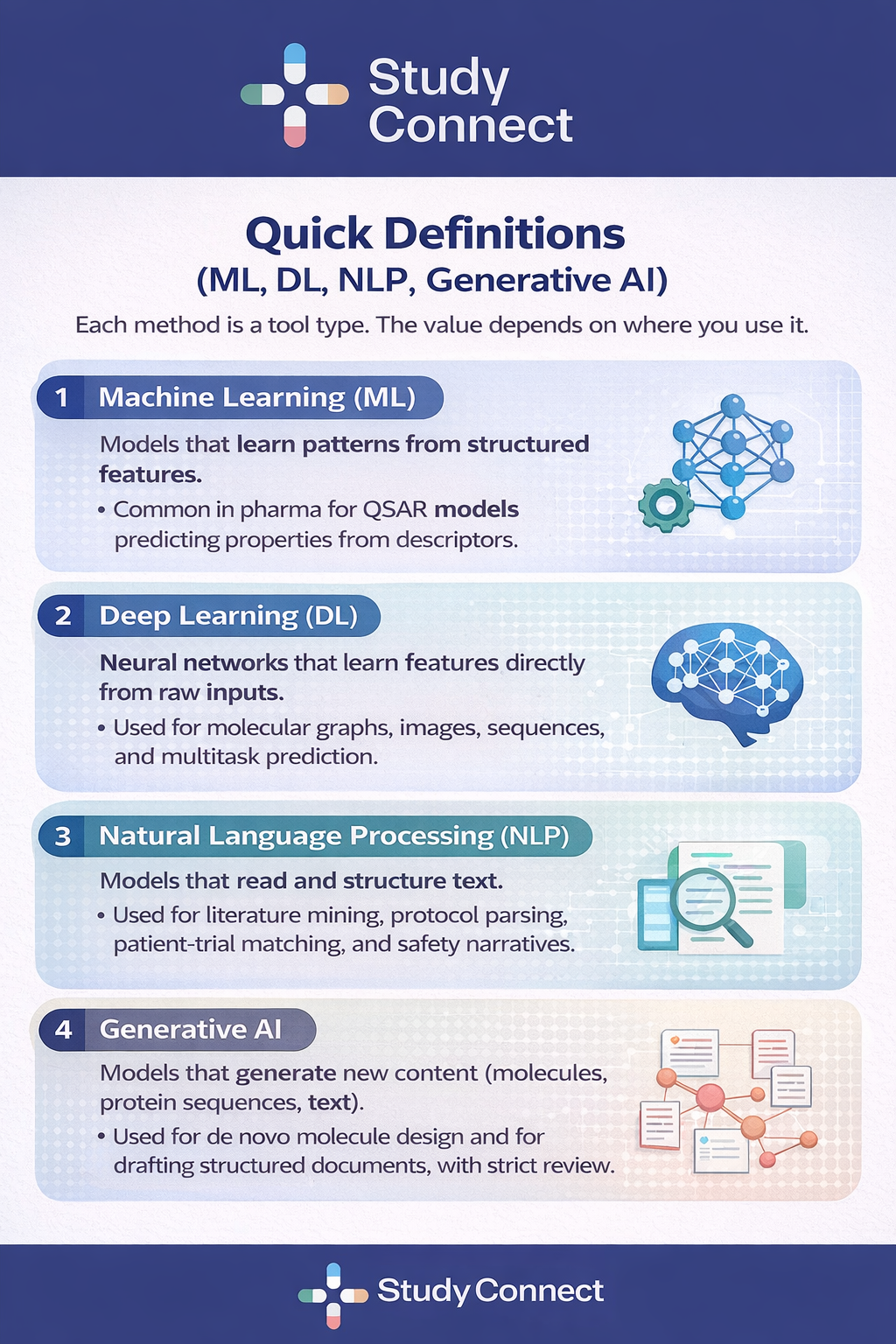
What each method is good at
The best teams pick methods based on thedecision, not on hype.
ML
Good at: tabular prediction,smaller datasets, baseline models
Not good at: unstructuredinputs, learning complex representations
Risk: false confidence if yourfeatures leak information
Deep Learning
Good at: complex patterns inmolecules, sequences, images
Not good at: small noisydatasets without strong validation
Risk: black-box behavior,harder to debug failure
NLP/ LLMs
Good at: extracting evidence,mapping eligibility criteria, summarizing text
Not good at: being trustedwithout citations and checks
Risk: hallucinations, subtleerrors in clinical logic
GenerativeAI
Good at: exploring chemicalspace, proposing candidates for constraints
Not good at: proving efficacyor safety
Risk: optimizing for what youcan measure, not what matters in humans
Where explainability matters most:
· FDA-facing decisions
· Safety and pharmacovigilanceworkflows
· Trial eligibility logic andsubgroup impact
Drug Discovery & Drug Development
Many AI projects fail because discovery and development teams mean different things by success. This split makes your KPIs clearer.

Drug discovery: From Target to Candidate (Early Risk)
Discovery covers the work before you have a development candidate.
It includes target identification, hitfinding, lead optimization, and candidate nomination.
AI often works best here because:
· Feedback loops can be faster (assays and design cycles)
· You can test more hypothesescheaply before synthesis
· Outcomes like enrichment andproperty prediction are measurable
Drug Development: From Pre-clinical to Approval (Execution Risk)
Development covers pre-clinical enabling,clinical trials, safety, regulatory, and manufacturing.
Constraints are tighter because data issensitive and workflows are regulated.
AI can still help, especially in trial execution:
· Protocol design and Feasibility
· Patient Pre-screening and Matching
· Monitoring and Pharma Covigilance triage
Stages of Drug Discovery and Development
Here is the pipeline list we will follow in the map:
1. Target identification &validation
2. Hit discovery (virtualscreening / HTS support)
3. Lead optimization (potency,selectivity, ADMET)
4. Preclinical (tox, PK/PD,biomarkers)
5. Clinical trials (design,recruitment, monitoring)
6. Regulatory & safety (PV,signal detection)
7. Manufacturing (processoptimization, QA)
The Pipeline Map:
Where AI fits in each stage
Think data in -> decision out at every step. If you cannot name the decision, you cannot validate the AI.
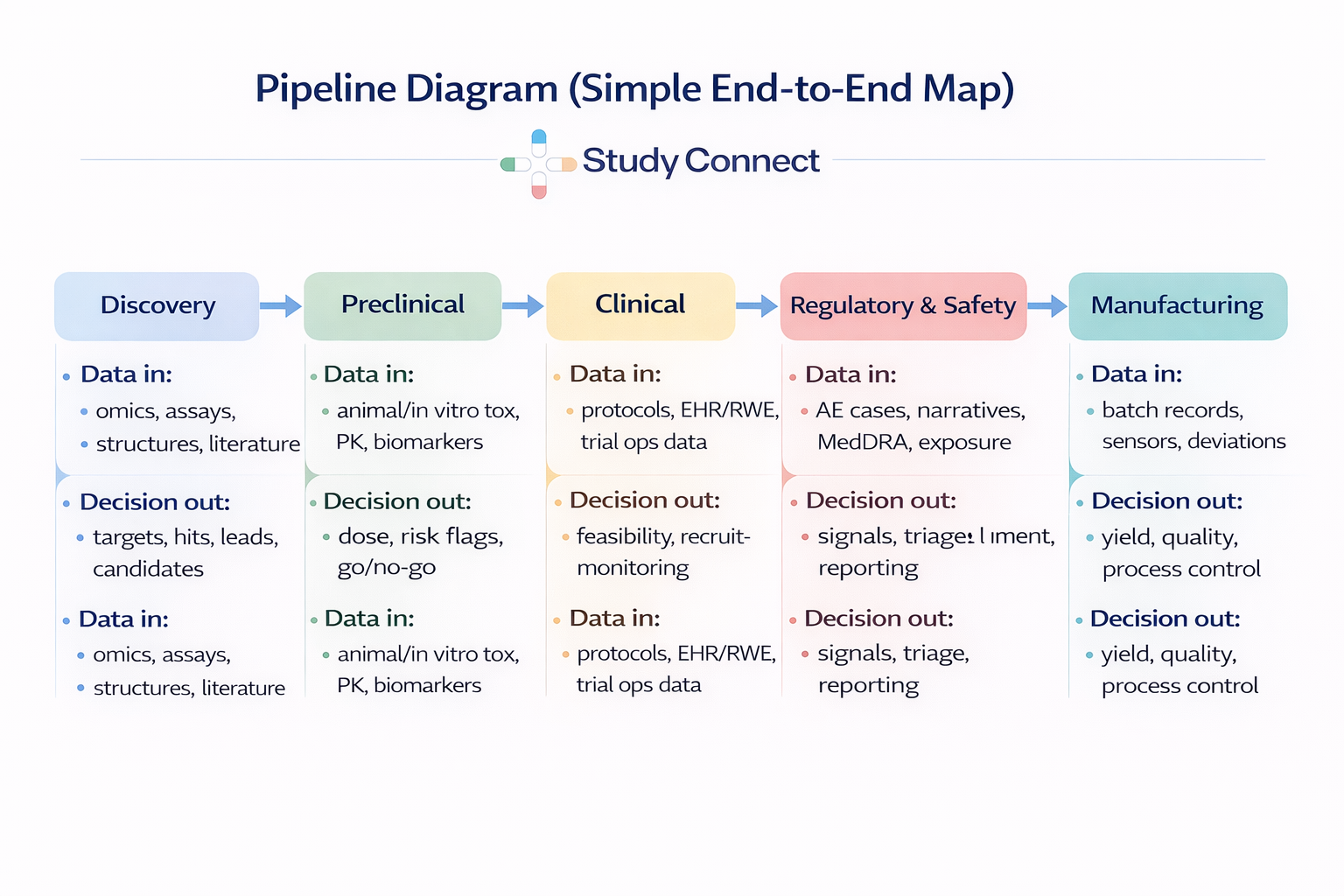
Target Identification & Validation
Target ID is where you decide what biology to bet on. If you pick the wrong target, everything downstream is expensive noise.
Common AI applications:
· Multi-omics target prioritization (genomics, proteomics, single-cell)
· Pathway and network coherence scoring
· Linking genetic signals to druggability
· CRISPR and perturbation data integration for plausibility
Minimum bar :
· Replication in an independent cohort
· Plausibility checks (pathways,tissue expression, known biology)
· Confounding checks (batch-effects, population structure)
Common failure modes:
· Batch effects that look like Biology
· Spurious correlations from siteor platform differences
· Target "novelty" that disappears when replicated
If you are unsure whether your target makes clinical sense, expert review can save months. In StudyConnect conversations, investigators often catch endpoint mismatch early, before teams spend on assays that do not map to human disease.
In our experience, the fastest way to reduce translational risk is simple: Put your Hypothesis in front of real clinicians early. StudyConnect helps teams connect with verified experts and uses AI-powered user research to extract structured, decision-ready insights from those conversations.
If you’d like help pressure-testing your program, email us at support@studyconnect.org.
Hit Discovery: Virtual Screening
Virtual screening is one of the clearest measurable-win zones for AI. The goal is not magic molecules. It is enrichment: test fewer compounds andfind hits faster.
AI-driven virtual screening vs classic HTS:
· HTS: physically test largelibraries; expensive and operationally heavy
· AI screening: rank andprioritize; then validate prospectively in wet lab
Proof points
· In an Atomwise/AtomNet virtualscreening campaign across 318 targets, reported 73% success rate (projects with at least one bioactive compound)
· Average of ~85 compounds tested per project
· Average of ~4.6 active hits
· Average hit rate of ~5.5%
Source: the AtomNet prospective study in Scientific Reports ([Naturepaper](https://www.nature.com/articles/s41598-024-54655-z.pdf))
To run a meaningful AI-driven virtual screening campaign, you need a solid data foundation. This includes clearly defined assays with proper controls, a labeled set of known actives and inactives (even if the dataset is small), and—when available—relevant protein structures or binding site features. Historical benchmarks are also important so you can compare enrichment performance against prior campaigns or established baselines. Without these elements, it becomes difficult to evaluate whether the model is genuinely improving decision-making or simply reproducing noise.
To ensure the work goes beyond a slide deck and reflects real scientific value, the process must be structured and prospective. First, freeze the model and ranking rules so that no adjustments are made after seeing results. Then select the top-ranked compounds along with a random baseline group for comparison. Run the assay prospectively in the lab, and finally report enrichment relative to the baseline while documenting both successes and failure cases. Transparent reporting of where the model fails is just as important as where it succeeds, as it determines whether the approach is robust enough for continued use.
Tools that show up a lot in practicalworkflows:
· RDKit descriptors, fingerprints, filtering, and data prep. It is open source andbusiness-friendly (BSD license), with strong Python support.
· ChEMBL has a curated source of bioactive molecules and drug-like properties to seedmodels and baselines.
Lead optimization in drug discovery often consumes significant time and budget because teams must balance potency, selectivity, and developability under uncertainty. AI is most useful here when it can predict early ADMET risk flags (e.g., solubility, clearance proxies, toxicity risks), learn structure–property relationships across projects, and support explicit multi-objective optimization. It works best when data comes from standardized panels with consistent labels, experiments can be rapidly re-tested to close the loop, and the team agrees on the true optimization goal rather than chasing vanity metrics. AI performance degrades when labels differ across CROs or assay formats, when scaffold leakage occurs, or when teams optimize docking scores without biological context. At minimum, validation should include time-split testing to approximate real deployment and external validation on genuinely new chemotypes.
Scaffold leakage occurs when training and test sets share core chemical scaffolds, allowing models (e.g., QSAR or GNNs) to recognize close analogs and produce inflated metrics such as AUROC or RMSE. This commonly happens with random splits that keep similar compounds in both sets, giving a false sense of generalization. To reduce leakage, use scaffold-based splits, add time-split validation when timestamps are available, and report performance on structurally novel chemotypes.
In preclinical settings, AI can support toxicity flagging from multi-assay panels, dose selection using PK/PD proxies, and biomarker modeling to link mechanism with measurable signals. However, translation to humans remains a major limitation, as animal and in vitro patterns do not always predict human biology. Before trusting such models, assess calibration (whether risk scores are meaningful beyond ranking), robustness across labs and assay formats, and failure modes on known toxic liabilities. Ultimately, data quality matters more than model complexity: public datasets like ChEMBL, PubChem, and PDB are valuable but messy, and non-reproducible training data leads to non-reproducible models.
Clinical AI in trials is not just about predicting outcomes; it often creates measurable value by removing operational friction that delays studies. High-impact applications include protocol parsing and complexity prediction, site selection and feasibility analysis, EHR/RWE-based patient matching and prescreening, and monitoring for missed visits, protocol deviations, or emerging safety patterns. Real-world evaluations show meaningful gains: Mendel.ai’s oncology prescreening demonstrated a 24–50% increase in correctly identified eligible patients compared to standard practice, while reducing eligibility-to-identification time from 19 days (breast cancer) and 263 days (lung cancer) to minutes. Source Similarly, TrialGPT reported a 42.6% reduction in screening time for patient recruitment and trial matching tasks (Nature Communications). These improvements directly affect timelines and budgets. Source
Before deployment, guardrails are essential. Teams should conduct bias checks across age, sex, race/ethnicity (where available), and sites; monitor exclusion patterns to understand who may be systematically missed; and define clear escalation rules specifying when human oversight overrides AI recommendations.
A silent run is a safer validation approach where the model operates in the workflow but does not influence decisions. It runs in the background so teams can compare its recommendations to actual human decisions without affecting patient safety or trial integrity. This approach helps measure real-world performance, identify integration failures (e.g., mapping errors, missing data fields, flawed logic), and assess subgroup performance before scaling. This is also where clinical experts are essential. Eligibility criteria are full of edge cases, and AI can miss real-world workflow constraints.

Regulatory and Safety: Pharmacovigilance (PV) and Signal Detection
In pharmacovigilance, regulators prioritize sensitivity, traceability, and auditability. AI systems are typically used for triage and prioritization rather than making final safety decisions. Common applications include adverse event (AE) intake triage, narrative summarization and field extraction, MedDRA coding support, and signal detection using historical baselines. At minimum, systems should be back-tested on known historical signals, include high-sensitivity modes for serious events, maintain full audit trails (who saw what and what changed), and operate on reproducible pipelines with locked evaluation datasets. Transparency and documentation are as important as performance.
MedDRA Coding in Pharmacovigilance and AI Support
MedDRA coding involves mapping adverse event descriptions to standardized regulatory terms, enabling consistent reporting across trials and agencies. AI can assist by suggesting likely MedDRA terms from free-text narratives, flagging inconsistencies across cases, and improving reviewer speed during high-volume periods. The preferred approach is “AI suggests, human confirms,” with logs of suggested terms, accepted terms, and overrides to ensure auditability.
Manufacturing: Process Optimization and Quality Assurance
In manufacturing, AI focuses on consistency and control. Typical applications include predictive maintenance, deviation detection, yield optimization, quality prediction from sensor data, and batch anomaly detection. Required data includes structured batch records, timestamped sensor streams, and deviation annotations within controlled GxP environments. Because change control is strict, models must be versioned, retraining must be validated, and documentation is essential alongside performance.
Use Cases by Data Type
AI capability depends on the quality and structure of available data. Organizations should begin with a realistic audit of existing datasets.
Omics Data (Genomics, Proteomics, Single-Cell)
Omics data is most useful for target identification, disease subtyping, and biomarker discovery. Success depends on strong metadata, batch correction planning, and independent cohort replication. Key risks include confounding (site effects, ancestry, sample handling) and poor generalization if validation is weak.
Chemistry and Bioassay Data (QSAR, GNNs, Docking, HTS)
This dataset family underpins small-molecule AI, supporting hit prioritization, property prediction, and molecular design. Inputs typically include molecular structures (e.g., SMILES), assay outcomes, and computed descriptors. Outputs include predicted properties, toxicity flags, and ranked compound lists. Robust validation requires scaffold or time-based splits, external validation on new chemical series, and honest baseline comparisons. Resources such as ChEMBL and RDKit are commonly used.
Imaging Data (Pathology and Radiology)
Imaging AI supports biomarker discovery and endpoint consistency when labels are reliable. Use cases include pathology feature extraction and radiology-based response prediction. Common pitfalls include scanner drift, inconsistent annotation, and shortcut learning. External validation and ongoing drift monitoring are critical.
EHR and Real-World Data (FHIR/OMOP)
EHR and real-world data can accelerate cohort finding, phenotyping, trial matching, and safety monitoring, but privacy, bias, and missingness are major challenges.Data should be mapped to common models such as OMOP or FHIR, with strong de-identification and access controls. A safe rollout pattern includes retrospective back-testing, a silent pilot phase, and monitored limited deployment.
Literature & Documents (NLP for Papers, Patents,Protocols)
Natural language processing (NLP) is most effective when positioned as evidence support rather than decision replacement. Its primary value lies in helping teams manage scale and information overload while keeping humans in the review loop. Common applications include literature mining to identify target–disease links, synthesizing evidence to assess biomarker plausibility, supporting protocol drafting, and extracting potential adverse event signals from narratives under strict validation controls.
A critical warning is that hallucinations and citation errors remain real risks. Any NLP system used in regulated or scientific contexts should require citation verification and human confirmation before conclusions are accepted or acted upon.
If you want a grounded view of how practitioners debate this, see community discussions like this thread on [AI for drugdiscovery]

AI in Drug Discovery and Development:Evidence, Risks, and Practical Implementation Guide
Hit Discovery / Virtual Screening
Clear enrichment metrics and fast wet-labfeedback are critical in AI-driven hit discovery. The AtomNet campaign data(318 targets, 73% success rate, ~5.5% hit rate) is a strong example ofprospective validation evidence. Nature paper: https://www.nature.com/articles/s41598-024-54655-z.pdf
Trial Operations
AI-driven prescreening and patient matchingcan significantly reduce coordinator burden and time. Mendel.ai demonstrated a24%–50% improvement in correctly identifying eligible patients and reducedeligibility-to-identification time from days to minutes. Springer paper:https://link.springer.com/content/pdf/10.1007/s43441-019-00030-4.pdf
TrialGPT reported a 42.6% reduction inscreening time in a user study. Nature Communications:https://www.nature.com/articles/s41467-024-53081-z.pdf
The ecosystem is rapidly maturing, withnearly 350 AI-driven drug discovery companies globally. ET Pharma report:https://pharma.economictimes.indiatimes.com/news/pharma-industry/ai-revolutionising-drug-discovery/117916035
Infrastructure and Compute
For compute-heavy workloads such as proteinmodeling, large-scale screening, and multimodal training, infrastructurematters. Teams often use GPU cloud platforms such as Nebius(https://nebius.com/) to run training and screening jobs. However, governanceand cost control remain essential.
Main Limits, Risks, and How to Fix Them
Data Quality Issues
Most failures in AI projects are not modelproblems but data, workflow, and governance issues. Common issues includemissingness in EHR data, inconsistent labels across sites, batch effects inomics and assays, and duplicates inflating performance metrics. Practical fixesinclude standardizing assay definitions, enforcing metadata requirements,deduplicating datasets, implementing batch correction plans, and conductinglabel adjudication.
Bias and Generalization
Models that work in one population may failin another, creating ethical and compliance risks. Minimum expectations includesubgroup performance reporting, monitoring subgroup drift post-deployment, anddocumenting training data representation. Practical steps include stratifiedevaluation, fairness reviews, and post-deployment monitoring.
Data Leakage and Overfitting
Data leakage is one of the most commoncauses of AI failure in production. Chemistry leakage may occur throughscaffold leakage via random splits or duplicate compounds across datasets.Clinical leakage can occur when features encode future information or siteidentifiers act as shortcuts. Safeguards include time splits, scaffold splits,locked test sets, external validation, and domain expert review.
Interpretability and Auditability
For FDA-facing decisions, traceability isessential. Teams must define intended use, maintain versioning of data andmodel artifacts, ensure reproducible training and evaluation reports, andmaintain audit logs. FDA overview: https://www.fda.gov/science-research/science-and-research-special-topics/artificial-intelligence-drug-development
Implementation: Build vs Buy, MLOps, and Governance
Build vs Buy
Build when the use case involvesproprietary data, core IP, and internal ML expertise. Buy when speed, standardworkflows, and compliance documentation support are required.
Minimum Validation by Stage
Target Identification requires independentcohort replication and biological plausibility. Virtual Screening requiresclear assay definitions and prospective wet-lab validation. Lead Optimizationrequires time-split and scaffold-split validation with external chemotypetesting. Trial Design requires back-testing and silent run pilots.Pharmacovigilance requires historical back-tests and high sensitivity forserious events.
MLOps in Pharma
MLOps includes data provenance tracking,model registries, validation reports, drift alerts, retraining rules, androllback plans. In GxP environments, model changes must follow controlledchange management processes.
Governance and Compliance
Key controls include de-identification,least-privilege access, clear IP terms, secure logging, review boards, andaudit-ready documentation. Trust readiness requires clearly defined intended use, validation evidence packages, reproducibility, subgroup analysis,and documented change management.
The next wave of AI in pharma focuses onintegration rather than isolated models. Multimodal foundation models combiningchemistry, biology, text, and EHR data may improve translation signals. Proteinlanguage models and structure-enabled design expand computable hypothesis spacebut still require wet-lab validation. Closed-loop design-make-test-learnsystems may compound gains if supported by robust operational infrastructure.
Evidence-Based Examples
AtomNet prospective campaign:https://www.nature.com/articles/s41598-024-54655-z.pdf
Mendel.ai oncology prescreening:https://link.springer.com/content/pdf/10.1007/s43441-019-00030-4.pdf
TrialGPT screening reduction:https://www.nature.com/articles/s41467-024-53081-z.pdf
Discussion thread:https://www.reddit.com/r/biotech/comments/1crm21j/the_coming_wave_of_ai_in_drug_industry/
Preclinical out-of-pocket cost per approveddrug is estimated at $430M. DiMasi:https://healthtechnetwork.com/wp-content/uploads/2017/12/DiMasi.pdf
Phase I to approval success rate is approximately 7.9%. BIO report:https://go.bio.org/rs/490-EHZ-999/images/ClinicalDevelopmentSuccessRates2011_2020.pdf
Practical 30/60/90 Day Action Plan
30 Days: Define one bottleneck, writeintended use, define baseline metrics, and validation plan.
60 Days: Secure data, standardize labels, run retrospective back-test, andconduct silent run or prospective validation.
90 Days: Controlled pilot rollout with audit logs, subgroup review, driftmonitoring, and scale criteria.
AI in pharma works best for hypothesisgeneration and prioritization. Humans validate, especially when decisionsaffect patients. Pick one bottleneck, validate prospectively, and keep clinicalexperts close to the loop.
AI works best in pharma when it is tightly connected to real clinical workflows and validated prospectively. If you’re building or evaluating AI for drug discovery, trial operations, or safety, StudyConnect can help you pressure-test your approach with verified clinicians and investigators before you make expensive commitments. To explore collaboration or get support, reach out to support@studyconnect.org.


















